Free Online PDF OCR Tool
Top Advantages of Using Our PDF OCR Tool

Accurate OCR for Scanned PDFs and Images
Our tool uses advanced Optical Character Recognition technology to extract text from scanned PDFs, images, and other non-editable documents with remarkable accuracy. It recognizes printed text in a wide variety of formats, maintaining paragraph structure, line breaks, and general layout. Whether you're working with forms, books, contracts, or receipts, the extracted content closely mirrors the original for a seamless editing experience.
The OCR engine is designed to detect and adapt to various font styles, sizes, and formatting nuances, ensuring that even multi-column layouts and tables are processed accurately. This makes the tool especially useful for students, professionals, and researchers who need fast and reliable results. You no longer have to waste time retyping or correcting poor conversions - just upload, scan, and edit.
Browser-based and Effortlessly Accessible
One of the biggest advantages of our free PDF OCR tool is that it works entirely online, directly in your browser - no installations, plug-ins, or updates required. It's compatible with all modern devices and operating systems, including Windows, macOS, Linux, iOS, and Android. You can access it from a laptop, desktop, tablet, or smartphone, allowing you to convert documents anytime, anywhere.
This level of accessibility means there are no technical barriers for users of any experience level. Whether you're a tech-savvy developer or someone simply needing to extract text from a document quickly, the interface is clean, intuitive, and free from distractions. You don't need to create an account, and there are no hidden limitations - just a smooth, straightforward OCR experience.


Secure File Handling and Privacy Protection
We understand that many documents contain personal or sensitive information, which is why file security is a top priority in our system. Every file you upload is processed securely using encrypted connections, and we never store your files after the conversion is completed. Your documents are automatically deleted from our servers, reducing the risk of data leaks or unauthorized access.
Our commitment to privacy ensures that you can use the tool for confidential materials, such as medical records, legal contracts, business reports, or academic transcripts, with complete confidence. Unlike some platforms that retain or analyze your files, our service is designed to give you full control over your data. You get professional-grade results without compromising your privacy.
Extract Text from Scanned PDFs in Three Simple Steps
-
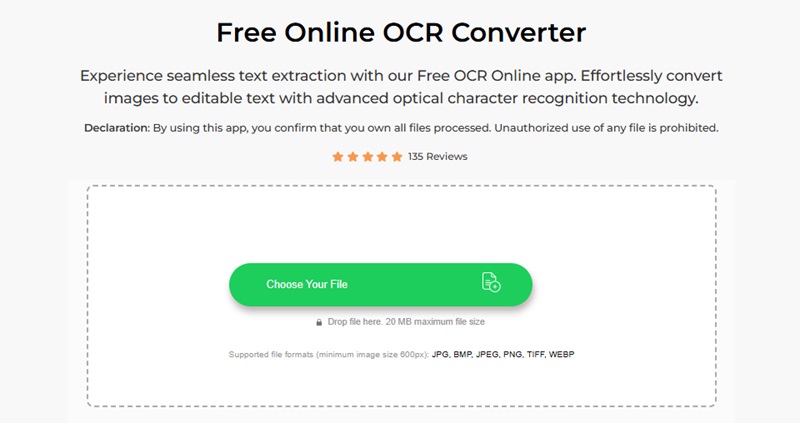
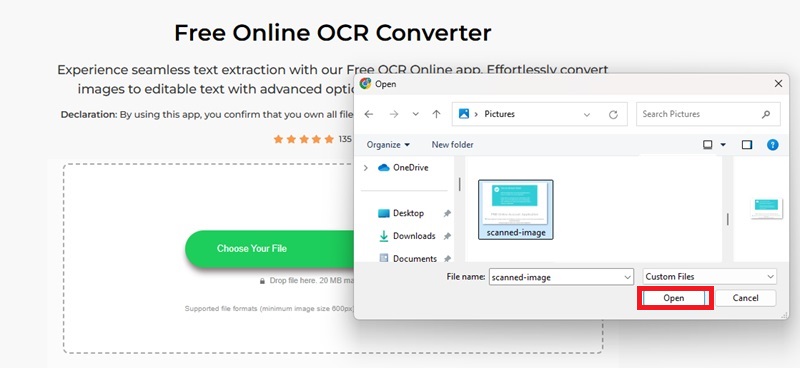
01Upload Your Scanned PDF or Image File
Click "Choose Your File" or drag and drop your scanned PDF or image directly into the OCR area.
-
02Select the output format as HTML.
Select your desired output format, and click "Start OCR." Our system will automatically process the file and recognize the text.
-
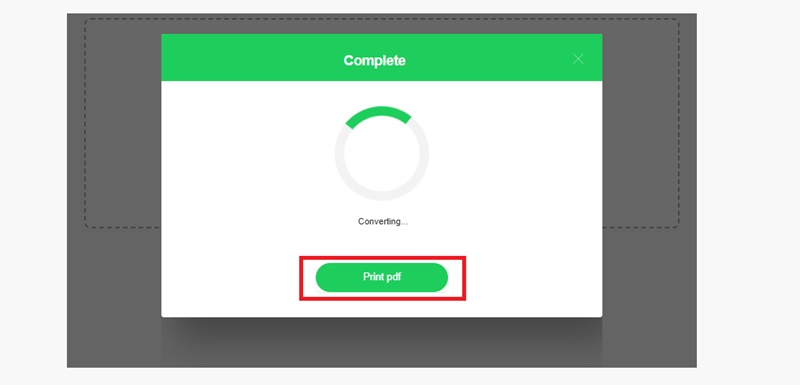
03Download the Extracted Text
Once the OCR is complete, click the "Download" button to get your fully editable and searchable document.
FAQs About PDF OCR Online
Yes, the tool is designed to extract text from scanned PDFs and image-based documents with high precision. It uses advanced Optical Character Recognition (OCR) technology to detect printed characters, even from complex layouts or low-resolution scans. Whether you're processing books, contracts, forms, or reports, the tool maintains a close match to the original structure, minimizing the need for manual corrections.
No downloads or installations are required to use this tool. It runs entirely online within your web browser, meaning you can use it from any device - desktop, laptop, tablet, or mobile - without needing to install additional software or plug-ins. This allows for instant access and use, regardless of whether you're using Windows, macOS, Linux, or a mobile operating system.
Yes, your file privacy and data security are fully protected throughout the OCR process. All file transfers are encrypted, and uploaded documents are automatically deleted from our servers after the conversion is complete. We do not store, share, or view your documents - your files remain private and secure at all times.
The tool supports scanned PDFs as well as common image formats, including JPG, PNG, and BMP. After conversion, you can download the recognized text in various formats, including plain text (TXT), Microsoft Word (DOCX), or Rich Text Format (RTF). This flexibility enables you to easily edit, repurpose, or archive your extracted content in the format that best suits your workflow.
Yes, our OCR engine supports multiple languages to accommodate global users and a wide range of document types. You can select the language that matches your document before starting the OCR process to improve recognition accuracy. This ensures the proper handling of different characters, accents, and scripts - including non-Latin alphabets such as Chinese, Arabic, and Cyrillic.